Hello,
I am writing this topic because I saw some jobs running on RTX GPU and A100 GPU while these two cards don’t have the same utility.
-
RTX cards are good for single (or half) precision computing: Machine Learning
-
A100 cards are good for double precision computing: Molecular Dynamics and Hydrodynamics
In FP32 (without using Tensor Cores):
-
RTX3090: 35.58 TFLOPS for ~1.2k ChF
-
RTX3080: 29.77 TFLOPS for ~0.8k ChF
-
RTX2080Ti: 13.45 TFLOPS
-
A100: 19.49 TFLOPS for ~10k ChF
-
P100: 9.526 TFLOPS
In FP64:
-
All the RTX cards: ~0.5 TFLOPS
-
P100 cards: 4.763 TFLOPS
-
A100 cards: 9.746 TFLOPS
If you use an RTX3090 for FP64 computing you use only 1/64th of the card and make it unavailable for other users, it is ridiculous… (btw you are also ruining your priority for almost nothing).
If you use a P100 or A100 card for FP32 you use a card more expensive than a RTX3090, less efficient and make it unavailable to other users that might need it… Except if you use the tensor cores of the A100 for ML training, then A100 is more performant (432 tensor cores vs 328 for the RTX3090). The P100 GPUs do not have tensor cores !
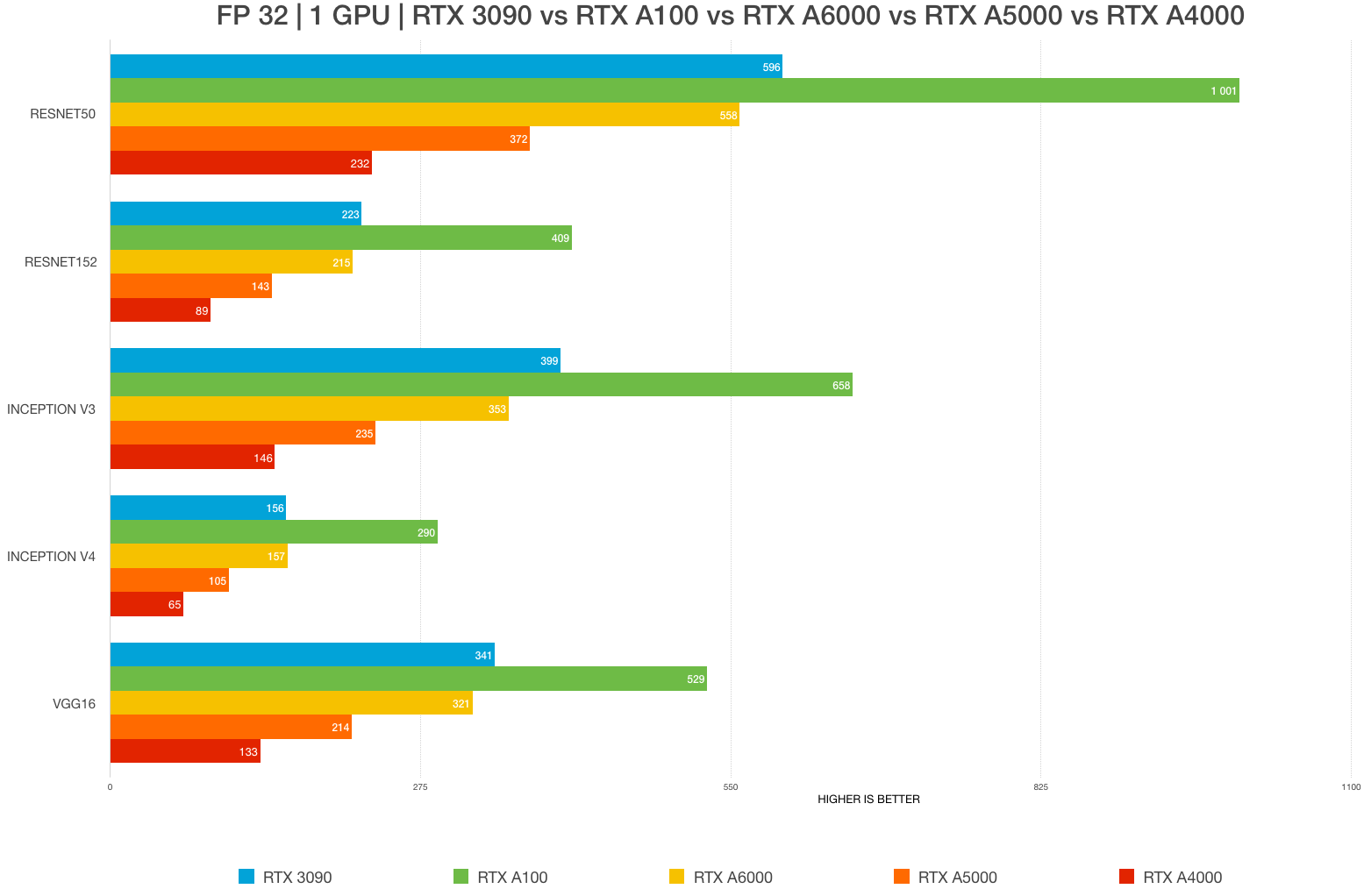
(Best GPU for deep learning in 2022: RTX 3090 vs. RTX 3080 Ti vs A6000 vs A5000 vs A100 benchmarks (FP32, FP16) – Updated – | BIZON Custom Workstation Computers. Best Workstation PCs and GPU servers for AI, deep learning, video editing, 3D rendering, CAD.)
If you need FP64 you can add this line in your batch: #SBATCH --constraint=DOUBLE_PRECISION_GPU, then you will get only P100 and A100 cards ![]() (Thanks to Yann Sagon) .
(Thanks to Yann Sagon) .
I hope it will help,