Theory
On a HPC cluster such as Baobab, the resources are shared between the user community. For this reason it’s important to use them wisely. An allocated resource is unavailable for others during the complete lifespan of the job. The issue arise when the resource is allocated but not used.
Definition: on the HPC world, when we talk about CPU, we mean core. A standard compute node has 2 physical CPUs, and 20 cores. So we say this node has 20 CPUs.
The resources available on a cluster such as Baobab are:
- CPUs, which are grouped in partitions
- GPGPUs which are accelerator for software which support them
- memory (RAM) per core or per node, 3GB by default
- disk space
- time, duration of the computation
There exists three family of job with different resource needs:
- mono threaded, such as Python, plain R, etc. They can only use one CPU.
- multi threaded, such as Matlab, Stata-MP etc. They can use in best case, all the CPUs of a compute node
- distributed such as Palabos. They can spread tasks on various compute nodes. Each task (or worker) require one CPU. Keyword to identify such program could be OpenMPI.
- hybrid each tasks of such a job behave like a multi-threaded job. Not very common.
On the cluster, we have two type of partitions with a fundamental difference:
- with resources allocated per compute node: shared-EL7, parallel-EL7
- with resources allocated per cpu: all the other partitions
Bad CPU usage.
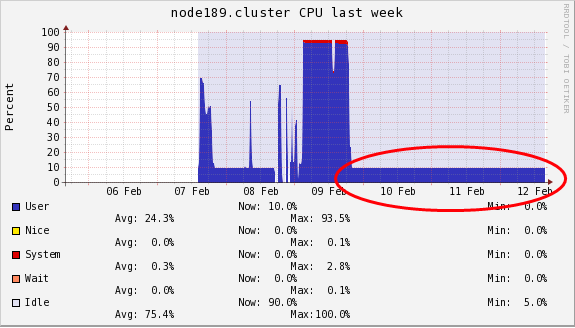
Let’s take an example of a mono threaded job. You should clearly use a partition which allows to request a single CPU, such as mono-shared-EL7 and ask one CPU only. If you ask the wrong partition type or too much CPUs, the resources will be reserved for your job but only one CPU will be used. See the screenshot below of such a bad case where 90% of the compute node is idle.
Bad memory usage.
Another misuse of the resource, is to ask too much RAM without using it. Baobab have many compute nodes with 48GB. If you request for example 40GB of RAM and 1 CPU, only two other CPU of this compute node may be allocated for another job, the remaining will stay unused by lack of memory. This is ok as long as you really use the memory. But in this case, if you job can benefit of more CPU, feel free to request all the other cores of this compute node. You can check the memory usage during the job execution or after.
Bad time estimation
If you submit a job and request 4 days of compute time and your job run effectively for 10 minutes, your time estimation is bad. It’s important for the scheduler that your time estimation is correct. A couple of hours of overestimation is ok. It’s important to have more or less correct time estimation due to the fact that slurm doesn’t only put new job in a fifo queue, but has a backfill mechanism that allows to launch a job that is later in the queue sooner if it doesn’t disturb other job. See the picture below for an explanation.

source: Scheduling. Slurm Training15. Salvador Martin & Jordi Blasco (HPCNow!)
Conclusion
You can see on the screenshot below the overall usage of the CPU resource during a whole day.
The goal is to increase this usage to around 80% which is considered the maximum on a general purpose cluster. So, help us to reach this goal and, use the resource wisely!
Thanks for reading ![]()
